Research
My current work investigates how humans use frames of reference, how minds plan and learn to plan, behavior programming, dualities of learning and meta/transfer/curriculum learning, and analytic tools for studying minds and models of minds.
Human Parallel Use of Spatial Reference Frames
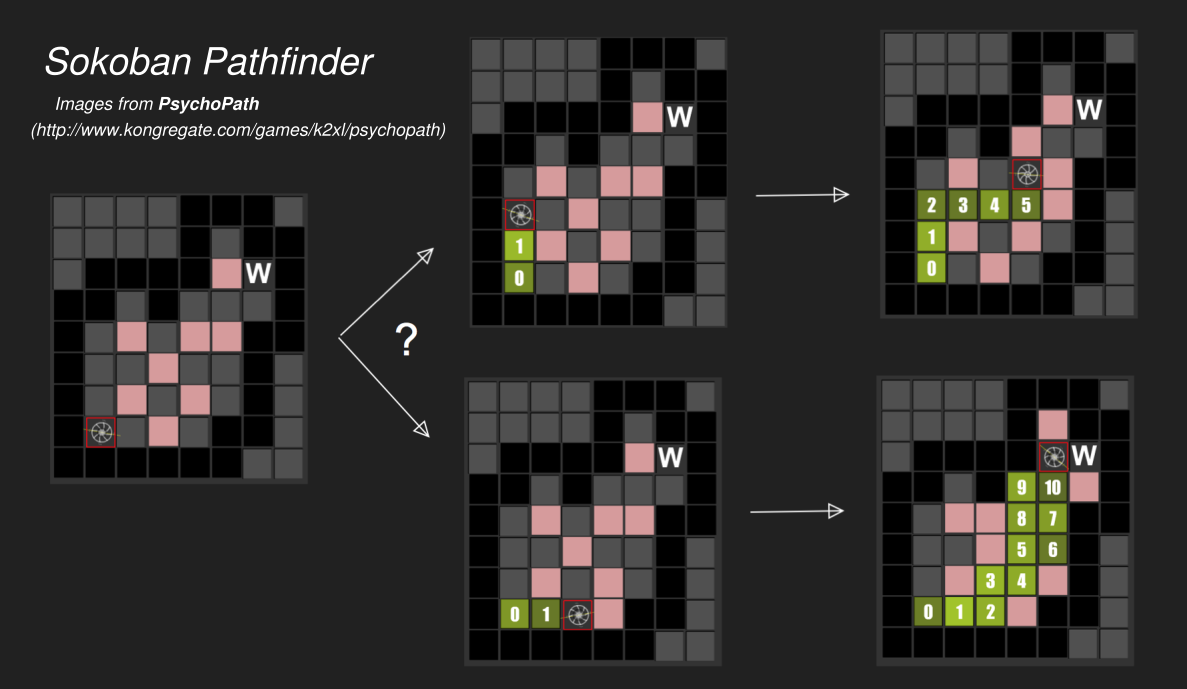
An academic research experiment series investigating whether humans learn to navigate better with a curriculum in a way that is similar to neural networks. This experiment tested individuals' ability to learn to navigate a maze in a browser. The broader series of experiments investigates the fitness of neural network models of cognition to actual human cognition.An exciting research project I designed and led was a cognitive science experiment conducted with Stanford's PDP Lab on human spatial cognition. This work extended my undergraduate thesis on how neural networks learn to navigate terrains and solve pathfinding problems. One of our most interesting findings was that AI models trained on simpler, shorter tasks developed a better ability to solve complex paths than models trained solely on the hardest tasks given the same resources. Inspired by this, our lab hypothesized that humans and neural networks might learn in similar ways. To test this, we designed a follow-up experiment to investigate whether humans, too, would benefit from a curriculum-based approach to the same mathematical pathfinding problem.
The project posed several design and technical challenges. We had to translate the abstract problem into an intuitive experiment interface suitable for human subjects, requiring thoughtful UI adjustments and accommodations. An interesting design adaptation came from troubles translating our maze problem to a grid - but we solved the problem by rotating and staggering the maze interface. Technically, I built the experiment website in JavaScript (now offline) by heavily adapting other experiment website code. Then I developed a data collection and processing pipeline using PHP and Python. I also integrated Mechanical Turk libraries to automate subject validation and payments. Altogether, this project involved numerous distinct moving technical parts, all of which had to fit together seamlessly. Throughout, I balanced rigorous software development, while ensuring that every design choice aligned with our cognitive science objectives and the methodological standards of scientific research.
What made the project especially compelling was its unified goal: exploring whether humans and neural networks solve problems in similar ways. Though one study engineered neural networks and the other tested human behavior, both followed the same design logic, offering insight into how learning, planning, and computation might converge across minds and machines. As a developer, I used tools I knew, learned and applied tools that were useful, brought different pieces together, worked with others when I needed their expertise, and kept the big-picture standards and goals in mind all throughout.
Pathfinder
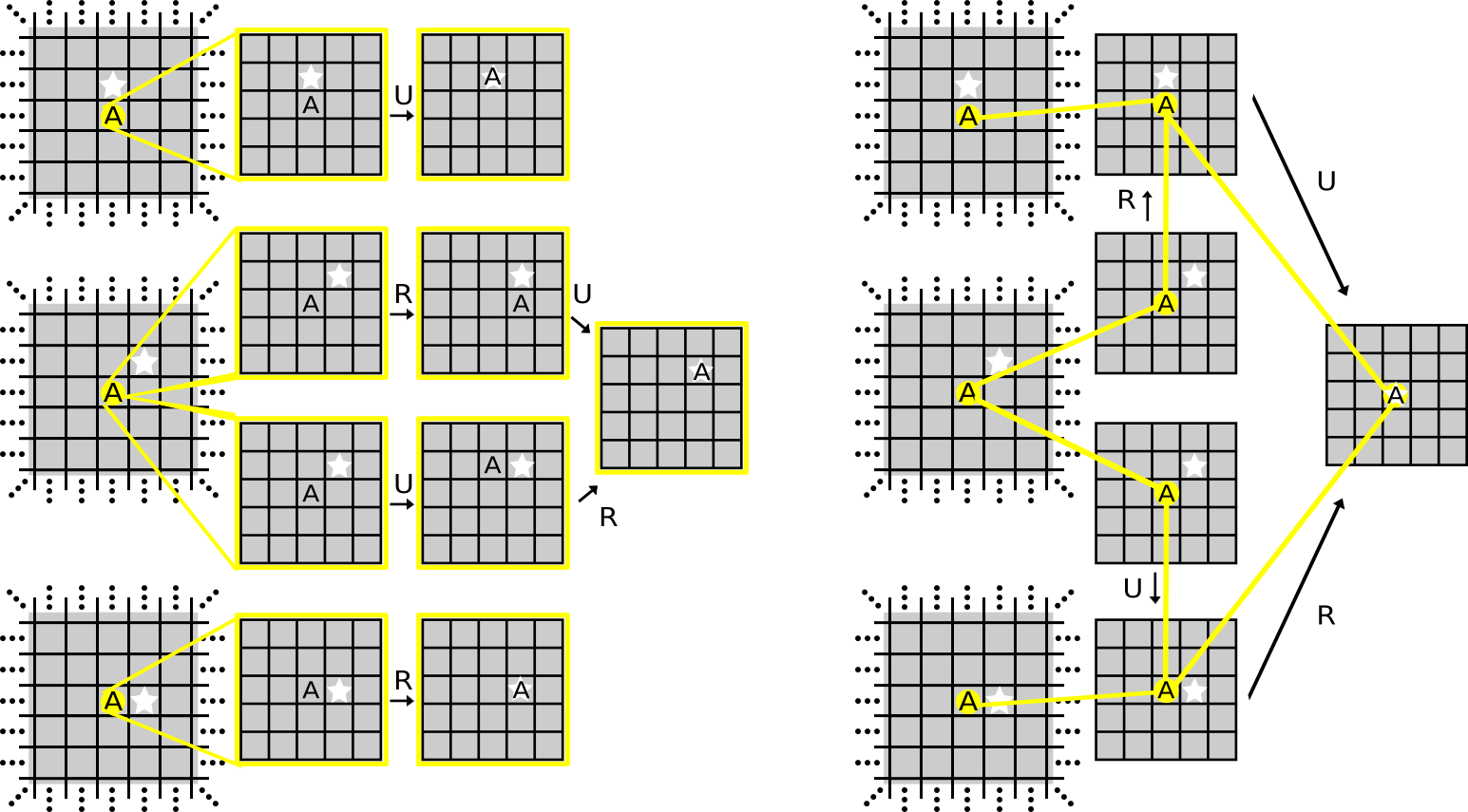
Frames of Reference for Neural Pathfinding Navigation , 2017, Senior Thesis project with non-authors A. Lampinen and J. McClelland. Full abstract: Two cognitive visuospatial methods for representing object locations are Egocentric refer- ence frames, which place objects relative to a special central entity, and Allocentric reference frames, which place objects on a stationary world. Humans have been shown to selectively use each reference frame, but it is unclear why humans use certain frames in certain situations. This work examines Deep-Q Reinforcement Learning Artificial Neural Networks that solve path-finding navigational puzzles using the two reference frames as models of human neural populations attempting the same puzzles. We provide a computational explanation for why humans generally use egocentric frames for navigational challenges, which is centered around cognitive skill transfer learning. Our results support the plausibility of connectionist cognitive planning as well as indicate the advantages that curriculum learning provides for teaching neural networks to plan effectively.

Modular Internal Attention Network
First Implementation (02/17) and Second
Proposal Paper (04/17).
Using only tensor operations common to deep learning, a second-order model is proposed that uses a
distributed attention over its internal components. By giving the network the ability to selectively use
its own resources, the network can reduce catastropic intereference once trained. Aspects of this
project are continuing. See this CMU paper for a similar
concept.

A diagram of the core structure of the Modular Internal Attention Network.
Multiple Recurrent Attention Network
Inspired by Recurrent Models of Visual Attention, we
developed a visual attention model that could process visual input in a way that was
biologically-realistically parallel. This project explored 'glimpses', virtual saccades, as internal
attentional mechanisms.
Due to a fascinating but unfortunately project-halting bug in provided
code, we discovered that neural networks with two weighted outputs that only receive backpropagation
signals from one output have the ability to learn internal representations that make effective layerwise
random fixed projections of the second output. To our knowledge, this result is absent in literature and
is a route for further exploration.

An example of an MRAM model with two attendants and six glimpses learning an MNIST digit.
Normalized Gradient Descent (todo)
See also my other projects, often on related topics.
I have been working in Stanford's PDP lab for one year now, and the majority of my written research has come with this mutual engagement. Headed by Dr. Jay McClelland, the PDP lab works in the domain of computational cognitive science within psychology, and we investigate the basis of cognition. The lab's current primary project is an investigtion as to how individuals learn mathematics through a high-school level. Day-to-day, many lab members use and study neural networks as tools for modeling and simulation and the work bleeds into machine learning & AI, statistics, physics, linguistics, math, neuroscience, and philosophy in addition to various aspects of psychology.